项目概要
~95%
操作时间节省
5min
优化后每月耗时
5~6h
优化前每月耗时
项目背景
集团每月要求按照收入成本名表格式提交 KE30 利润中心数据,原始 SAP 导出数据字段缺失、收货方未分配、跨客户跨物料收入成本分配率计算后按要求分配问题,需人工核对处理 5~6 小时/月。
解决方案
Python 全自动处理:清洗原始 KE30 数据 → 双重分配模型(客户维度 + 物料维度)→ 输出符合集团报表格式的10号表和分配后明细表,全程约 5 分钟内完成。
读取KE30数据
→
字段清洗映射
→
客户维度分配
→
物料维度分配
→
分配前后比对
→
输出两张报表
核心难点
双重分配模型设计:先按客户维度分配(有客户无物料→有客户有物料),再按物料维度分配(无客户有物料→有客户有物料);关联方单独处理不参与分摊;分配率计算需处理分母为零及 NaN/inf 的边界情况,分场景计算各自分配率,按照分配率进行分摊。
技术栈
项目文档
一、背景与目标
SAP KE30 导出的利润中心数据存在:收货方"未分配的"需补全、省份需要匹配、产品性质修改、客户名称截断需映射、成本收入存在无物料行需计算分配率分摊给有物料行。手工处理约 5~6 小时/月,自动化后压缩至 5 分钟内,节省约 95%。
二、四部分处理流程
| 部分 | 内容 | 输出 |
|---|---|---|
| 第一部分 | 数据清洗:筛选期间、补全收货方、字典映射、物料类型映射、计算收入金额、关联方标注 | 10号表.xlsx |
| 第二部分 | 客户维度分配:有客户无物料的收入/成本,按分配率分摊给有客户有物料行 | 已分配收入金额、按客户已分配成本 |
| 第三部分 | 物料维度分配:无客户有物料的成本,按物料分配率分摊给有客户有物料行 | 按物料成本已分配金额 |
| 第四部分 | 结果整理:数值保留两位小数,关联方特殊处理,输出最终文件 | 分配后的.xlsx |
三、分配逻辑说明
客户分配率 = 无物料收入(成本)/ 有物料收入(成本);已分配金额 = 原金额 × (1 + 分配率)。物料分配率 = 无客户成本 / 有客户成本;无客户有物料行分配后最终成本归零。关联方不参与任何分摊,按实际成本直接取值。
效果展示
以下为集团报表数据清洗与双重分配全流程交互演示,点击「播放」查看完整执行过程。
录屏演示
注:该项目运行后直接输出文件,输出速度受电脑运行速度影响。
输出过程录屏
示例文件
以下为项目相关文件截图。(注:此文件中的数据均已进行脱敏及适应性修改,与公司业务无直接关联,仅用于演示或测试用途。)
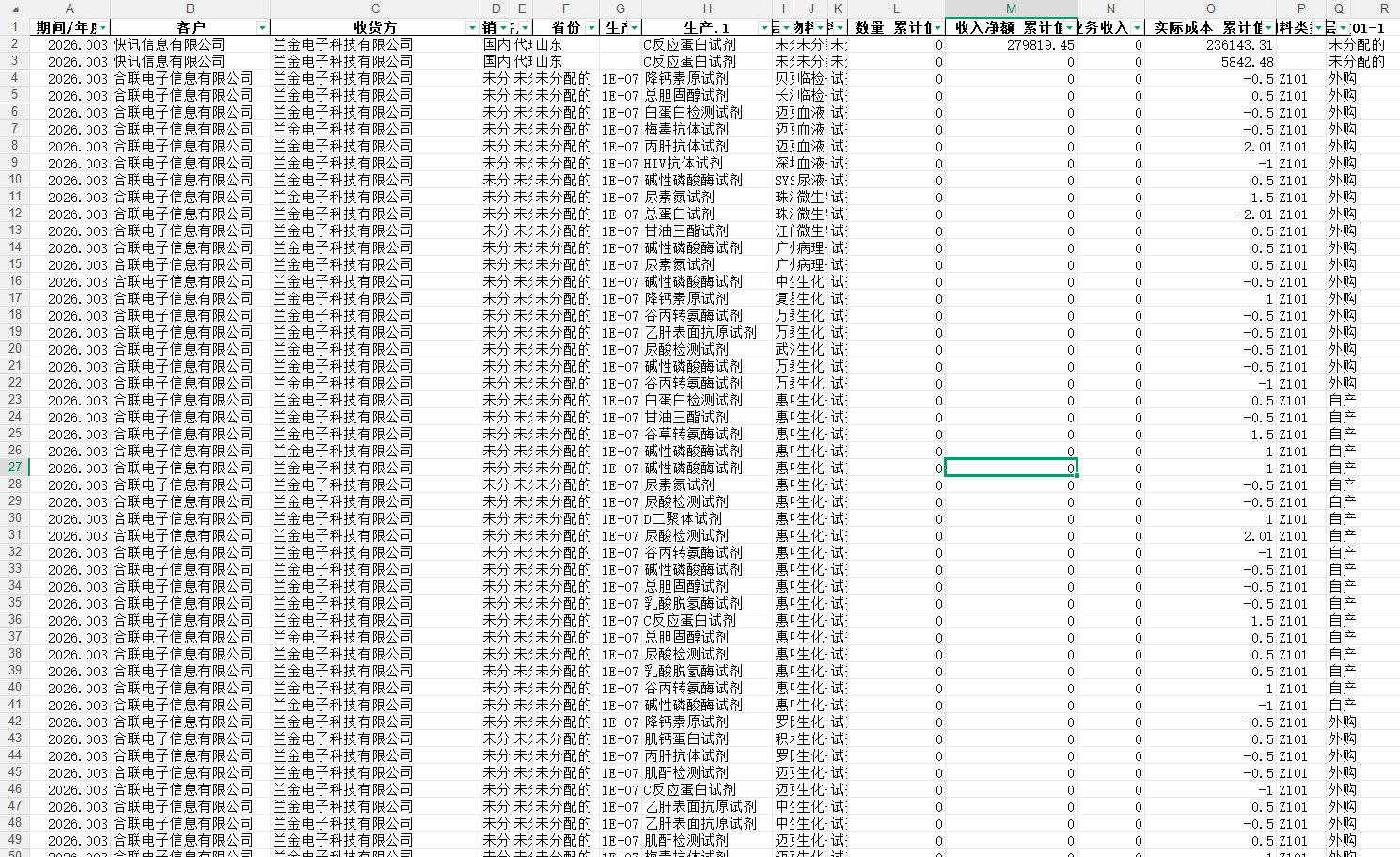
SAP KE30 原始导出数据
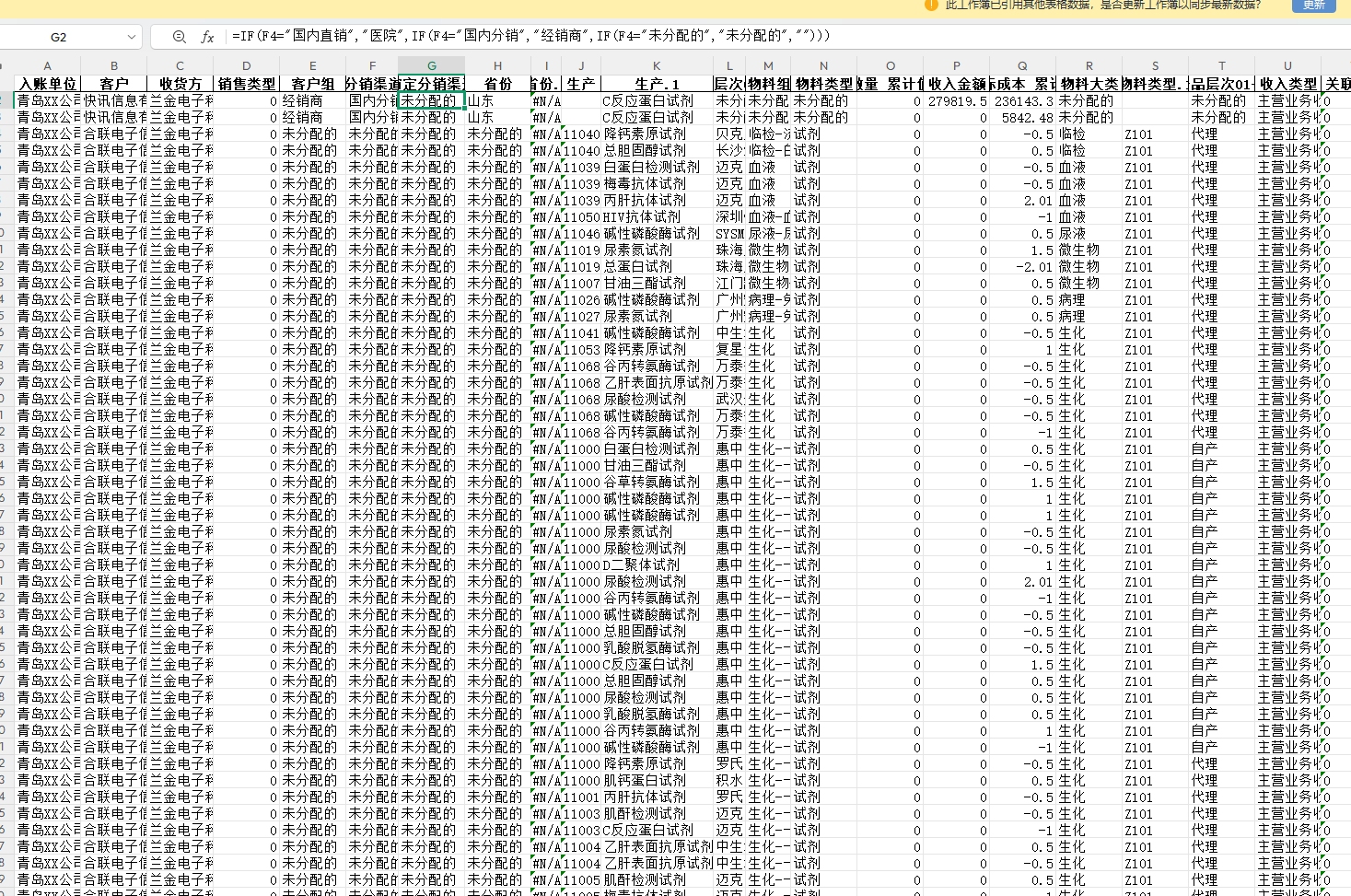
清洗后的10号表格式
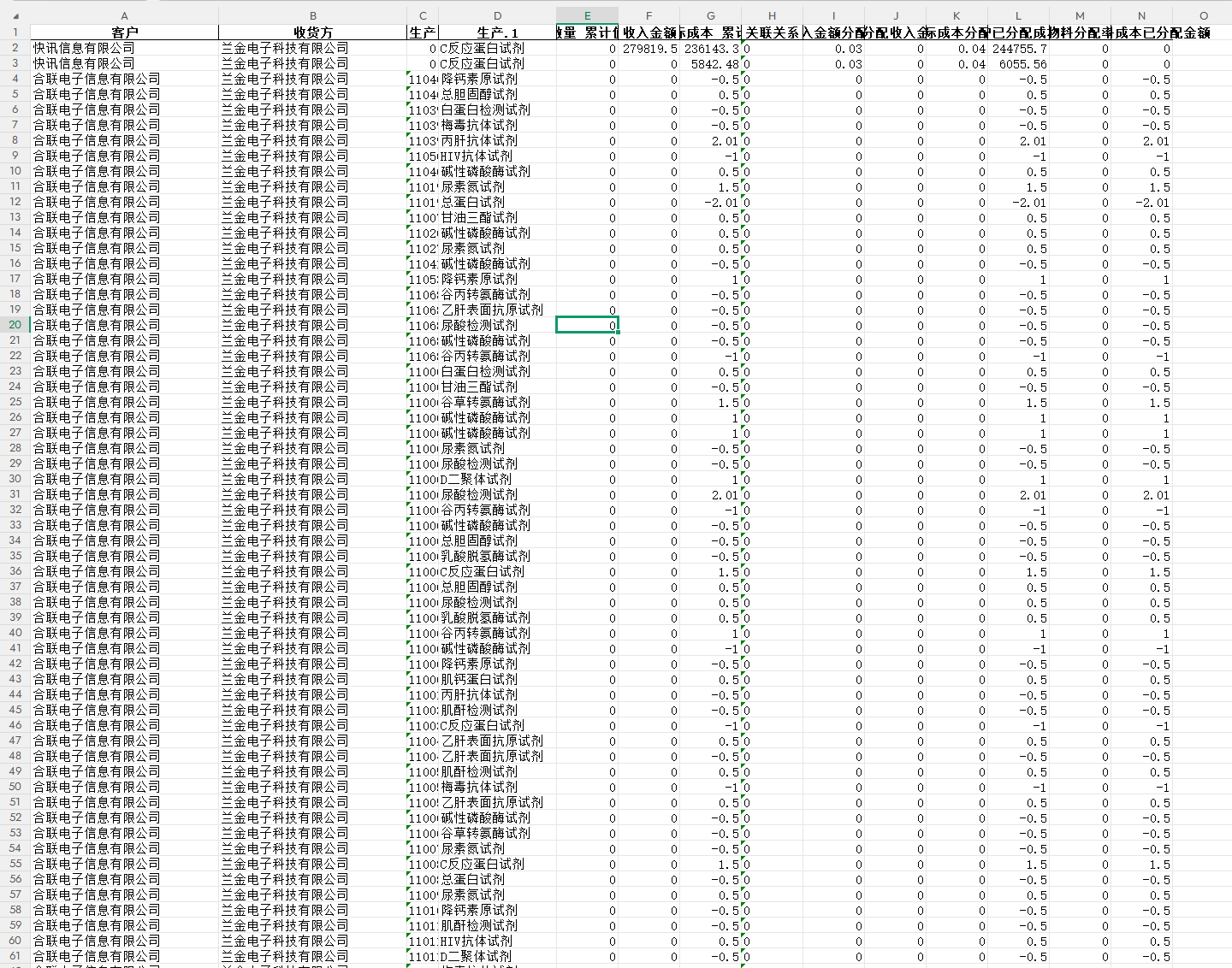
分配后的最终明细表
源码
10hao.py — 集团报表数据清洗与双重分配
import pandas as pd
import numpy as np
# ========================基础配置========================================================
# ke3010.xlsx为SAP系统导出的原始ke30数据表
path = r"C:\Users\Yuyu\Desktop\work\3.集团报表数据清洗\ke30.xlsx"
# 10号表.xlsx为集团报表要求格式
path_10 = r"C:\Users\Yuyu\Desktop\work\3.集团报表数据清洗\10号表.xlsx"
# 分配后的.xlsx 为按照集团报表10号表的要求进行物料客户分配
path_finally=r"C:\Users\Yuyu\Desktop\work\3.集团报表数据清洗\分配后的.xlsx"
# 读取ke30.xlsx数据
ke30 = pd.read_excel(path, sheet_name='Sheet1', dtype=str)
# ==========================结束========================================================
# =================第一部分 ke30基础表按照集团报表要求格式修改=================================
# 处理重复列名 - 手动添加后缀 ke30数据有双重复的列名为了便于数据提取修正 先修改重复列名
def handle_duplicate_columns(df):
numeric_col = pd.Series(df.columns)
# [numeric_col.duplicated()]标记每个元素是否为重复出现
for dup in numeric_col[numeric_col.duplicated()].unique():
# 找到所有重复列的位置
mask = numeric_col == dup
# 为重复列添加后缀 .1, .2, ...
numeric_col[mask] = [f"{dup}.{i+1}" if i != 0 else dup for i in range(mask.sum())]
df.columns = numeric_col
return df
# 应用重复列处理函数
ke30 = handle_duplicate_columns(ke30)
# 条件筛选和赋值 筛选需要处理年月份数据
ke30 =ke30.loc[ke30['期间/年度']=='2026.003',:]
# 筛选客户为医院的和收货方为未分配的 将收货方的未分配改成客户名称XXX医院
condition = ke30['客户'].astype(str).str.contains("医院")
condition2 = ke30['收货方'] == "未分配的"
# 取交集
result = condition & condition2
# 只修改筛选出来的数据
ke30.loc[result, '收货方'] = ke30.loc[result, '客户']
# 筛选客户名称结尾为站、所、中心的和收货方为未分配的 将收货方的未分配改成客户名称XXX站等
Condition3 = ke30['客户'].astype(str).str.endswith(("站", "所", "中心"))
Condition4 = ke30['收货方'] == "未分配的"
# 取交集
result2 = Condition3 & Condition4
# 赋值
ke30.loc[result2, '收货方'] = ke30.loc[result2, '客户']
# 字典映射替换 客户名称长度超出限制导致数据缺失 补全客户名称 产品性质 经销代理等修改
dictionary = {
'山东XXXXX分': '山东XXXXX分公司',
'浙江XXXXX实验室有限': '浙江XXXXX实验室有限公司',
'外购': '代理',
'代理商': '经销商'
}
# 字典映射 对表里的所有内容 进行替换
ke30 = ke30.replace(dictionary, regex=True)
# 物料类型映射 根据物料号映射对应的物料类型
value_to_type = [
('90000030', "动产租赁"),
('90000020', "维保服务"),
('90000051', "维保服务"),
('90000051', "维保服务"),
('90000210', "费用性成本")
]
# 只对生产列符合条件的列 修改对应的物料类型列
for code, type_name in value_to_type:
ke30.loc[ke30['生产'] == code, '物料类型'] = type_name
# 产品层次01-1赋值 将产品里包含产品1|产品2 取并集 满足一个就修改 这两种产品的对应产品层次修改为自产
condition5 = ke30['产品层次01-2'].astype(str).str.contains("产品1|产品2")
ke30.loc[condition5, '产品层次01-1'] = '自产'
# 将产品3的物料类型改为信息化产品
condition6 = ke30['产品层次01-2'].astype(str).str.contains("产品3")
ke30.loc[condition6, '物料类型'] = '信息化产品'
# 收入金额计算(pd.to_numeric转换为数值类型后计算 coerce处理缺失值返回nan ) 收入=收入+其他业务收入
ke30['收入净额 累计值'] = pd.to_numeric(ke30['收入净额 累计值'], errors='coerce')
ke30['其他业务收入 累计值'] = pd.to_numeric(ke30['其他业务收入 累计值'], errors='coerce')
ke30['数量 累计值'] = pd.to_numeric(ke30['数量 累计值'], errors='coerce')
ke30['实际成本 累计值'] = pd.to_numeric(ke30['实际成本 累计值'], errors='coerce')
ke30['收入金额'] = ke30['收入净额 累计值'] + ke30['其他业务收入 累计值']
# 物料大类赋值 提取物料组-前的数据
ke30['物料大类'] = ke30['物料组'].str.split('-').str[0]
# 其他列赋值
ke30['入账单位'] = '青岛XX公司'
# 因为原表需要自带公式 不能修改 此处直接为原表公式填充 也可以直接用merge进行匹配
ke30['销售类型'] = '=IFERROR(VLOOKUP($E5,关联关系!$G$6:$H$17,2,0),0)'
ke30['审定分销渠道'] = '=IF(F4="国内直销","医院",IF(F4="国内分销","经销商",IF(F4="未分配的","未分配的","")))'
ke30['省份.1'] = '=XLOOKUP(B4,关联关系!P:P,关联关系!Q:Q)'
# 收入类型赋值 生产为9000开头的这几个中的一个为其他业务收入 否则为主营业务收入
condition7 = ke30['生产'].astype(str).str.contains("90000030|90000020|90000051|90000001")
ke30['收入类型'] = np.where(condition7, '其他业务收入', '主营业务收入')
# 关联方处理 关联方不参与分配 要提前将关联方排除
company_list = [
"上海XXXX有限公司",
"上海XXXX云南分公司",
"上海XXXXXXXX有限公司",
"上海XXXXXXX有限公司",
# ... 其余公司
]
#对列表使用 isin(),判断是否在列表中 .astype(str) 返回一个 pandas Series(一列数据)
# Series 对象没有 .strip() 方法 .strip() 是字符串的方法 所以要先转str
condition8 = ke30['客户'].astype(str).str.strip().isin(company_list)
# 如果客户在关联方列表里将客户标记为合并范围内 否则为0
ke30['关联关系'] = np.where(condition8, '合并范围内', '0')
# 定义需要的列标签(按想要的顺序)
my_columns = [
'入账单位',
'客户',
'收货方',
'销售类型',
'客户组',
'分销渠道',
'审定分销渠道',
'省份',
'省份.1',
'生产',
'生产.1',
'产品层次01-2',
'物料组',
'物料类型',
'数量 累计值',
'收入金额',
'实际成本 累计值',
'物料大类',
'物料类型.1',
'产品层次01-1',
'收入类型',
'关联关系'
]
# 检查并处理可能不存在的列
existing_columns = [col for col in my_columns if col in ke30.columns]
# 定义并应用新的列标签
new_table = ke30[existing_columns]
# 保存清洗后的数据到10号表.xlsx
new_table.to_excel(path_10, index=False)
# 从10号表里取出需要的列内容 进行分配处理计算分配率等
column2 = [
'客户',
'收货方',
'生产',
'生产.1',
'数量 累计值',
'收入金额',
'实际成本 累计值',
'关联关系'
]
# 选取指定列column2复制数据到分配表
allocate = new_table[column2].copy()
# 处理这三列的数据变为数值格式 并且为空的改为nan
cols = ['实际成本 累计值', '数量 累计值', '收入金额']
for col in cols:
allocate[col] = pd.to_numeric(allocate[col], errors='coerce')
# 将数据写入分配后的表
allocate.to_excel(path_finally, index=False)
# =================================数据清洗结束==============================================
# ==================第二部分 将有客户无物料的收入成本分配到有客户有物料身上====================
# ------------------------------------有客户有物料---------------------------------------
# 筛选条件:
# 客户列不包含未分配的
# 生产列是空的
# 因为筛选出来的数据没有9000开头数据所以这个不设置不包含9000开头的条件
youkehuwuwuliao = (allocate['客户'].astype(str).str !='未分配的') & (allocate['生产'].isna())
# 根据客户将实际成本累计值和收入金额进行汇总 数据透视表 效果如下:
# 客户 实际成本累计值_无物料 收入金额_无物料 生产
# A 100 200 nan
youkehuwuwuliao_pivot = allocate[youkehuwuwuliao].groupby('客户')[['实际成本 累计值', '收入金额']].sum()
# -----------------------------------有客户无物料--------------------------------------------
# 筛选条件:
# 客户不包含未分配的
# 生产列不是空的
# 不包含9000开头数据
# 也不包含关联方的数据
pattern = '90000030|90000020|90000051|90000001|90000210'
# ~取非
youkehuyouwuliao = (
(allocate['客户'].astype(str).str !='未分配的') &
(~allocate['生产'].isna()) &
(~allocate['生产'].astype(str).str.contains(pattern, na=False) )&
(allocate['关联关系'] != '合并范围内')
)
# 根据客户将实际成本累计值和收入金额进行汇总 数据透视表 效果如下:
# 客户 实际成本累计值_有物料 收入金额_有物料 生产
# A 500 600 001
# B 400 450 002
youkehuyouwuliao_pivot = allocate[youkehuyouwuliao].groupby('客户')[['实际成本 累计值', '收入金额']].sum()
# --------------------------------有客户有物料与有客户无物料合并------------------------------------------------------
# 合并有客户无物料和有物料数据 效果如下:
# 客户 实际成本累计值_无物料 收入金额_无物料 实际成本累计值_有物料 收入金额_有物料
# A 100 200 100 200
# B 400 450 NAN NAN
fenpeilv =pd.merge(
youkehuwuwuliao_pivot,
youkehuyouwuliao_pivot,
on=None,
left_index=True,
right_index=True,
suffixes=('_无物料', '_有物料')
)
# --------------------------------------分配率计算--------------------------------------------------------------
# 计算分配率 效果如下:
# 客户 实际成本累计值_无物料 收入金额_无物料 实际成本累计值_有物料 收入金额_有物料 实际成本分配率 收入金额分配率
# A 100 200 500 600 100/500=0.2 200/600=0.3
# B 400 450 NAN NAN NAN NAN
fenpeilv['实际成本分配率'] = fenpeilv['实际成本 累计值_无物料'] / fenpeilv['实际成本 累计值_有物料']
fenpeilv['收入金额分配率'] = fenpeilv['收入金额_无物料'] / fenpeilv['收入金额_有物料']
# 将收入分配率表里的nan进行更改为0
fenpeilv[['收入金额分配率', '实际成本分配率']] = fenpeilv[['收入金额分配率', '实际成本分配率']].replace([np.inf, -np.inf], 0 ).fillna(0)
# ----------------------------------将分配率匹配到原始主表-----------------------------------------------------
# 将计算出来的收入和成本分配率 匹配到分配后的原始表 以分配后的表为主 只追加分配率不做任何修改
allocate = pd.merge(
allocate,
fenpeilv[['实际成本分配率', '收入金额分配率']],
on='客户',
how='left'
)
# 客户 实际成本累计值 收入金额 实际成本分配率 收入金额分配率 已分配成本金额 已分配收入金额
# A 100 200 0.2 0.3 0 0
# A 500 600 0.2 0.3 500*1.2=600 600*1.3=780
# B 400 450 0 0 400*1=400 450*1=450
#
# 根据匹配到的分配率 计算已分配收入金额 和 按客户已分配成本 这两列金额 .fillna(allocate['']) 二次兜底防止因分配率为NAN导致最后金额出现空值
allocate['已分配收入金额'] = (allocate['收入金额'] * (1 + allocate['收入金额分配率'])).fillna(allocate['收入金额'])
allocate['按客户已分配成本金额'] = (allocate['实际成本 累计值'] * (1 + allocate['实际成本分配率'])).fillna(allocate['实际成本 累计值'])
# ==========================================第二部分结束========================================================
# =========================================第三部分 将无客户有物料的成本分配到有客户有物料身上==========================
# ---------------------------------------------------筛选无客户有物料---------------------------------------------
# 筛选条件:
# 客户 = '未分配的'
# 生产列非空(有物料)
# 生产编码不是以 90000030/90000020/... 开头(排除特定内部物料)
# 关联关系不是 '合并范围内'(排除关联方)
wukehu = (
(allocate['客户'] == '未分配的') &
allocate['生产'].notna() &
~allocate['生产'].astype(str).str.contains(pattern, na=False) &
(allocate['关联关系'] != '合并范围内')
)
# 对无客户有物料的数据,按生产汇总【按客户已分配成本金额】
# 效果如下:
# 生产 按客户已分配成本金额_无客户
# 001 100
# 002 200
wukehu_pivot = allocate[wukehu].groupby('生产')['按客户已分配成本金额'].sum()
# ------------------------------------筛选有客户有物料-------------------------------------------------------------
# 筛选条件:
# 客户不是 '未分配的'
# 生产列非空
# 生产编码不是以 90000030/... 开头
# 关联关系 == '0'
youkehu=(
(allocate['客户'] != '未分配的') &
(~allocate['生产'].isna()) &
(
~allocate['生产'].astype(str).str.contains(pattern, na=False) &
(allocate['关联关系'] == '0')
)
)
# 对有客户有物料的数据,按生产汇总【按客户已分配成本金额】
# 效果如下:
# 生产 按客户已分配成本金额_有客户
# 001 500
# 002 300
youkehu_pivot = allocate[youkehu].groupby('生产')['按客户已分配成本金额'].sum()
# --------------------------------合并无客户有物料与有客户有物料(按生产)-----------------------------------------------------
# 内连接两个汇总表,只保留同时出现在两个集合中的生产编码
# 效果如下:
# 生产 按客户已分配成本金额_无客户 按客户已分配成本金额_有客户
# 001 100 500
# 002 200 300
fenpeilv2= pd.merge(
wukehu_pivot,
youkehu_pivot,
how='inner',
left_index=True,
right_index=True,
suffixes=('_有客户', '_无客户')
)
# --------------------------------------物料分配率计算--------------------------------------------------------------
# 物料分配率 = 无客户成本 / 有客户成本
# 表示:每一元有客户成本需要分摊多少无客户成本
# 效果如下:
# 生产 按客户已分配成本金额_无客户 按客户已分配成本金额_有客户 物料分配率
# 001 100 500 0.2
# 002 200 300 0.6667
fenpeilv2['物料分配率'] = fenpeilv2['按客户已分配成本金额_无客户'] / fenpeilv2['按客户已分配成本金额_有客户']
# 处理无穷大和缺失值:将无穷大置为0,缺失值填充0
fenpeilv2['物料分配率'] = fenpeilv2['物料分配率'].replace(
[np.inf, -np.inf], 0).fillna(0)
# ----------------------------------将物料分配率匹配到原始主表-----------------------------------------------------
# 以原始表 allocate 为主表,左连接物料分配率(按生产)
allocate = pd.merge(
allocate,
fenpeilv2,
on='生产',
how='left'
)
# ----------------------------------计算按物料成本已分配金额-----------------------------------------------------
# 规则:
# - 对于有物料分配率的行(即有客户有物料 或 无客户有物料中的交集生产):
# 按物料成本已分配金额 = 按客户已分配成本金额 * (1 + 物料分配率)
# - 对于无物料分配率的行,保持原按客户已分配成本金额不变
# - 特殊处理:无客户有物料且分配率非空的行,最终按物料成本已分配金额强制设为0
# (因为这些成本已经通过分配率转移给了有客户有物料的行)
allocate['按物料成本已分配金额'] = allocate.apply(
lambda row: row['按客户已分配成本金额'] * (1 + row['物料分配率'])
if pd.notna(row['物料分配率'])
else row['按客户已分配成本金额'],
axis=1
)
# 清理中间辅助列:仅对符合条件的行保留分配率等,其余置为缺失(可选,用于追踪)
valid_condition = youkehu | wukehu
allocate.loc[~valid_condition, ['物料分配率', '按客户已分配成本金额_有客户', '按客户已分配成本金额_无客户']] = pd.NA
# 无客户有物料的行,成本已全部分配出去,因此按物料成本已分配金额为0
allocate.loc[wukehu & allocate['物料分配率'].notna(), '按物料成本已分配金额'] = 0
# ----------------------------------后处理:数值格式化、特殊规则覆盖-----------------------------------------------
# 所有数值列保留两位小数
numeric_cols = allocate.select_dtypes(include=['number']).columns
allocate[numeric_cols] = allocate[numeric_cols].round(2)
# 关联关系为 '合并范围内' 的行,按物料成本直接取实际成本(不参与分摊)
allocate.loc[allocate['关联关系'] == '合并范围内','按物料成本已分配金额']=allocate['实际成本 累计值']
# 生产为空的行(无物料),已分配收入金额和按物料成本金额都设为0(没有物料不参与成本分摊)
allocate.loc[allocate['生产'].isna(), ['已分配收入金额', '按物料成本已分配金额']] = 0
# 最终全局处理无穷大和缺失值,全部填充0
allocate = allocate.replace([np.inf, -np.inf], 0).fillna(0)
# ==========================================第三部分结束========================================================
# =========================================第四部分 最终数据整理、列筛选与结果输出=========================================
# 定义最终需要保留的列
mycolumns = [ '客户',
'收货方',
'生产',
'生产.1',
'数量 累计值',
'收入金额',
'实际成本 累计值',
'关联关系',
'收入金额分配率',
'已分配收入金额',
'实际成本分配率',
'按客户已分配成本金额',
'物料分配率',
'按物料成本已分配金额'
]
# 从最终分配结果 allocate 中提取上述列,并创建独立副本,避免后续误修改原数据
allocate=allocate[mycolumns].copy()
# 将整理好的allocate数据框保存到指定路径
allocate.to_excel(path_finally, index=False)
print("已为您整理好集团报表,请查收。")
# ==========================================全部处理流程结束========================================================